![]()
![]()
</div>

pandas es un libreria de Python destinada al análisis de datos, que proporciona unas estructuras de datos flexibles y que permiten trabajar con ellos de forma muy eficiente. Pandas depende de Numpy, la librería que añade un potente tipo matricial a Python. Los principales tipos de datos que pueden representarse con pandas son:
Pandas proporciona herramientas que permiten:
En pandas existen tres tipos básicos de objetos todos ellos basados a su vez en Numpy:
Estas ultimas estructuras de datos (Panel, Panel4D y PanelND) permiten trabajar con más de dos dimensiones. Dado que es algo complejo y poco utilizado trabajar con arrays de más de dos dimensiones no trataremos los paneles aqui
Las series son arrays unidimensionales con indexación (arrays con índice o etiquetados), similar a los diccionarios. Pueden generarse a partir de diccionarios o de listas. De manera opcional podemos especificar una lista con las etiquetas de las filas.
Primero necesitamos cargar la librería correspondiente:
# cargar libreria Pandas y numpy
import numpy as np
import pandas as pd
El primer ejemplo que vamos a poner va a ser el de definir una estructura de datos "Series" que como ya comentamos es un array de datos unidimensional con idexación. Las "Series" se definen de la siguiente manera:
serie = pd.Series(data, index=index)Es decir, que en el primer parámetro le indicamos los datos del array y en el segundo parámetro los índices. Veamos un ejemplo de como crear una estructura "Series" simplemente con los valores a,b,c y un indexado por defecto.
serie = pd.Series(['a', 'b', 'c'])
serie
También se puede definir la etiqueda del index
serie = pd.Series(['a', 'b', 'c'], index=['pregunta1', 'pregunta2', 'pregunta3'])
serie
serie.pregunta1
En el caso de que usemos un diccionario, el nombre de las filas toma el valor de las keys del diccionario (index).
dict = {'pregunta1': 'a', 'pregunta2': 'b', 'pregunta3': 'c'}
serie = pd.Series(dict)
serie
serie.pregunta1
Podemos controlar tanto los datos que queremos incluir como su orden especificando el index:
serie = pd.Series(dict, index=['pregunta3', 'pregunta1', 'pregunta4'])
serie
Hay muchas otras formas de acceder a los datos, pero por simplicidad, aquí sólo veremos Series.loc[] por cuestiones de simplicidad. En la documentación se puede ver el resto de los métodos. Para seleccionar datos usamos los métodos loc, iloc e ix.loc permite seleccionar datos usando las etiquetas de filas y columnas, iloc basándose en posición e ix basándose tanto en etiquetas como posición. En el caso de una Serie, devuelve un único valor.
Series loc[etiqueta_fila]
Series iloc[indice_fila]
Series ix[indice/ "etiqueta_fila"]
serie = pd.Series([1,2,3,4], index=['a','b','c','d'])
serie
serie.loc['a']
serie.loc[['a','c']]
serie.iloc[2]
Para filtrar datos, le podemos pasar a la Serie una lista de valores lógicos (verdaderos y falsos) indicando las filas que nos son de interés.
serie = pd.Series([1,2,3,4], index=['a','b','c','d'])
serie[[True, False, True, False]]
En lugar de pasar una lista de valores lógicos podemos pasar directamente una prueba lógica.
serie[serie>=3]
Seleccionado de datos, primero creamos como ejemplo una serie y luego a partir de un diccionario para recordar
bacteria = pd.Series([10, 20, 14, 11],
index=['a', 'b', 'c', 'd'])
bacteria
bacteria_dict = {'a': 10, 'b': 20, 'c': 14, 'd': 11}
pd.Series(bacteria_dict)
seleccionando solo una etiqueta
bacteria['b']
bacteria[1]
bacteria[['a','b']]
seleccionando con condiciones
bacteria[(bacteria > 10) & \
(bacteria < 20)]
Siguiendo con el ejemplo de las bacterias podemos trabajar algunas operaciones básicas
bacteria = bacteria + 5 #sumando
bacteria
bacteria = bacteria + bacteria
bacteria
bacteria = bacteria > 30
bacteria
selección Española de fútbol:
| 1 | Casillas |
| 15 | Ramos |
| 3 | Pique |
| 5 | Puyol |
| 11 | Capdevila |
| 14 | Xabi Alonso |
| 16 | Busquets |
| 8 | Xavi Hernandez |
| 18 | Pedrito |
| 6 | Iniesta |
| 7 | Villa |
El DataFrame permite almacenar y manipular datos tabulados en filas de observaciones y columnas de variables.Los DataFrame se pueden crear de diferentes maneras, una forma común de crearlos es partir de listas o diccionarios de listas, de diccionarios o de Series. En los DataFrame tenemos la opción de especificar tanto el index (el nombre de las filas) como columns (el nombre de las columnas).
Hay varias maneras de crear un DataFrame. Una es usar un diccionario. Por ejemplo:
dict_listas = {'uno' : [1, 2, 3, 4], 'dos' : [4, 3, 2, 1]}
dataframe = pd.DataFrame(dict_listas)
dataframe
list_listas = [[1, 2],[3, 4],[4, 3],[2, 1]]
dataframe = pd.DataFrame(list_listas, columns=['uno', 'dos'])
dataframe
dataframe = pd.DataFrame(dict_listas, index=['a', 'b', 'c', 'd'])
dataframe
dataframe.loc[['a','b']]
#Combinando series
dict_series = {'dos' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd']),
'uno' : pd.Series([1, 2, 3], index=['a', 'b', 'c'])}
dataframe = pd.DataFrame(dict_series)
dataframe
#aqui hemos excluido la fila correspondiente a c y cambiamos el orden
dataframe = pd.DataFrame(dict_series, index=['d', 'b', 'a'])
dataframe
otro ejemplo de la creacion de un dataframe a partir de un diccionario
dict = {"country": ["Brazil", "Russia", "India", "China", "South Africa"],
"capital": ["Brasilia", "Moscow", "New Dehli", "Beijing", "Pretoria"],
"area": [8.516, 17.10, 3.286, 9.597, 1.221],
"population": [200.4, 143.5, 1252, 1357, 52.98] }
brics = pd.DataFrame(dict)
brics
Como se puede ver con el nuevo DataFrame brics, Pandas tiene asignada una clave para cada país como valores numéricos de 0 a 4. Si se desea tener diferentes valores de índice, por ejemplo el código del país de dos letras, tambien puede hacerce facilmente.
# Establecer el índice para brics
brics.index = ["BR", "RU", "IN", "CH", "SA"]
# Imprimir Brics con nuevos valores de índice
brics
brics[['country','capital']]
Tambien podemos guardar el nuevo dataframe como archivo csv
brics[['country','capital']].to_csv('./data/brics.csv', header=True, index=False)
#el header True guarda el contenido de la etiqueta de cada columna e index=False excluye el indice en el archivo csv
Al igual que con las Series, podemos controlar tanto los datos que queremos incluir como su orden especificando el index y/o columnas que nos interesen:
Otra manera de crear un DataFRame es importando un archivo csv usando Pandas. Ahora, el csv cars.csv es almacenado y puede ser importado usando pd.read_csv(ruta del archivo):
# Importar los datos de cars.csv: autos
cars = pd.read_csv('data/cars.csv')
# Print out cars
cars
Hay varias maneras de indexar un DataFrame de Pandas. Una de las más sencillas es usar la notación de corchetes.
En el ejemplo de debajo, se puede usar corchetes para seleccionar una columna del DataFrame cars. Puede usar corchetes simples o dobles. Los corchetes simples tienen salida a Pandas Series, mientras que los corchetes dobles tendrán salida a a Pandas DataFrame.
cars = pd.read_csv('data/cars.csv', index_col = 0)
# Imprimir la columna de país como Pandas Series
print(cars['cars_per_cap'])
# Imprimir la columna de país como Pandas DataFrame
print(cars[['cars_per_cap']])
# Imprima DataFrame con las columnas country y drives_right
print(cars[['cars_per_cap', 'country']])
Los corchetes también pueden usarse para acceder a observaciones (filas) desde un DataFrame. Por ejemplo:
cars = pd.read_csv('data/cars.csv', index_col = 0)
# Imprimir las primeras 4 observaciones
print(cars[0:4])
# Imprime la quinta, sexta y séptima observación
print(cars[4:6])
Tenemos un fichero csv con datos sobre origen, peso y tamaño de diferentes individuos de una especie
datos = pd.read_csv('data/analisis.csv', sep=';', skiprows=1, index_col=0)
datos
En muchas situationes del “mundo real”, los datos que queremos usar proceden de múltiples archivos. Frecuentemente necesitamos combinar estos archivos en un uniquo DataFrame para analizar los datos. El paquete pandas proporciona varios métodos de combinar DataFrames incluyendo join, merge y concat. concat permite concatenar Series y DataFrame. Mediante la opción axis, podemos controlar si la unión se debe hacer por filas o por columnas.
s1 = pd.Series([1,2,3,4], index=['a','b','c','d'])
s1
s2 = pd.Series([5,6,7,8], index=['a','b','c','d'])
s2
pd.concat([s1, s2])
from numpy.random import randn
df1 = pd.DataFrame(randn(4,2), index=['a', 'b', 'c', 'd'], columns=['c1', 'c2'])
df1
df2 = pd.DataFrame(randn(4,2), index=['a', 'b', 'c', 'd'], columns=['c1', 'c2'])
df2
#concatenando dataframes
pd.concat([df1, df2], axis=0)
pd.concat([df1, df2], axis=1)
df1 = pd.DataFrame(randn(4,2), index=['a', 'b', 'c', 'd'], columns=['c1', 'c2'])
df2 = pd.DataFrame(randn(4,2), index=['b', 'c', 'd', 'e'], columns=['c3', 'c4'])
df1.join(df2)
join mantiene todos las filas presentes en el df1 pese a que no se encuentren en el df2 y completando con NaN los datos faltantes. Este comportamiento se puede modificar usando la opción how.how=’outer’ incluirá también las filas presentes en el df2 y que no están en el df1 y how=’inner’ sólo mostrará las filas comunes a los dos DataFrame.
df1.join(df2, how='outer')
df1.join(df2, how='outer')
df1.join(df2, how='inner')
df = pd.DataFrame([{'Name': 'Chris', 'Item Purchased': 'Sponge', 'Cost': 22.50},
{'Name': 'Kevyn', 'Item Purchased': 'Kitty Litter', 'Cost': 2.50},
{'Name': 'Filip', 'Item Purchased': 'Spoon', 'Cost': 5.00}],
index = ['Store 1', 'Store 1', 'Store 2'])
df
df['Date'] = ['December 1', 'Januaryy 1', 'mid-May']
df
df['Delivered'] = True
df
df["Feedback"] = ['Positive', None, 'Negative']
df
adf = df.reset_index()
adf['Date'] = pd.Series({0: 'December 1', 2: 'mid-May'})
adf
Es de gran interes fusionar conjuntos de datos almacenados en diferentes archivos para producir un unico archivo final que incorpora toda la informacion. Para fusionar datos provenienes de diferentes archivos existen diferentes extrategias.
Consideremos el siguiente ejemplo:
staff_df = pd.DataFrame([{'Name': 'Kelly', 'Role': 'Director of HR'},
{'Name': 'Sally', 'Role': 'Course liaison'},
{'Name': 'James', 'Role': 'Grader'}])
staff_df = staff_df.set_index('Name')
staff_df
student_df = pd.DataFrame([{'Name': 'James', 'School': 'Business'},
{'Name': 'Mike', 'School': 'Law'},
{'Name': 'Sally', 'School': 'Engineering'}])
student_df = student_df.set_index('Name')
student_df
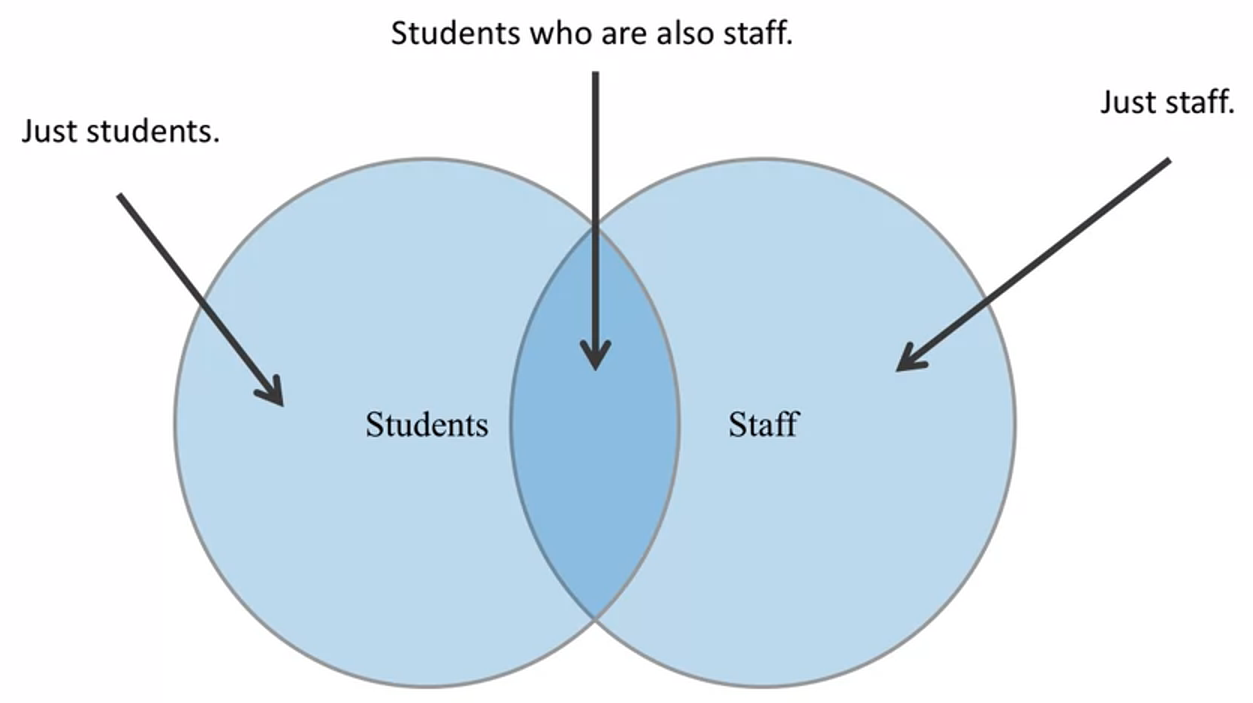
Fusiona la informacion completa proveniente de ambos conjuntos. Es importante mencionar que la existencia o no de un dato en un conjunto se realiza con repecto al indice que se elige.
Produce una lista de toda la gente sin importar si ellos son empleados o estudiantes y toda la informacion que se dispone para cada uno de ellos.
pd.merge(staff_df, student_df, how='outer', left_index=True, right_index=True)
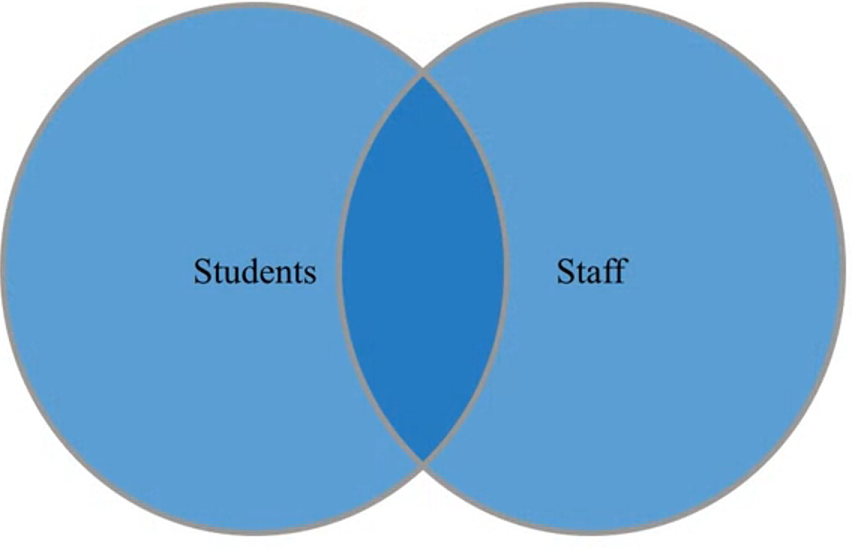
Fusiona la informacion que se encuentra en ambos conjuntos.
Produce una lista de la gente que es empleado y estudiantes al mismo tiempo y toda la informacion que se dispone para cada uno de ellos.
pd.merge(staff_df, student_df, how='inner', left_index=True, right_index=True)
Adicionalmente, existen dos casos de uso comunes para fusionar datos:
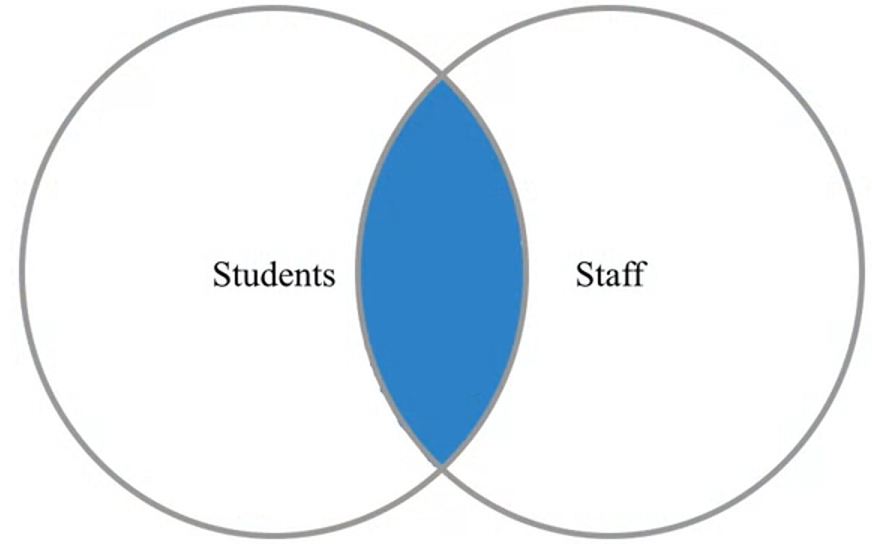
El resultado de esta operacion siempre contiene todos los elementos (registros) del conjunto izquierdo (es decir, el primer DataFrame mencionado en la consulta) independientemente de si existe un elemento correspondiente en el otro conjunto.
Produce una lista de todos los empleados sin importar si ellos son estudiantes o no y si un empleado es tambien estudiante muestra adicionalmente esta informacion.
pd.merge(staff_df, student_df, how='left', left_index=True, right_index=True)
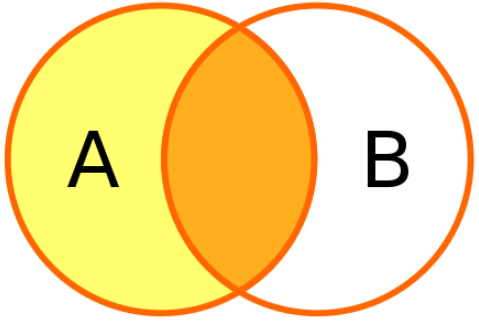
El resultado de esta operacion siempre contiene todos los elementos (registros) del conjunto derecho (es decir, el segundo DataFrame mencionado en la consulta) independientemente de si existe o no un elemento correspondiente en el otro conjunto.
Produce una lista de todos los estudiantes sin importar si ellos son empleados o no y si un estudiante es tambien empleado muestra adicionalmente esta informacion.
pd.merge(staff_df, student_df, how='right', left_index=True, right_index=True)
Otros parametros del metodo merge:
Los indices no son la unica opcion para realizar la union entre dos conjuntos de datos, tambien es posible usar las columnas.
staff_df = staff_df.reset_index()
student_df = student_df.reset_index()
pd.merge(staff_df, student_df, how='left', left_on='Name', right_on='Name')
Conflictos entre DataFrames
staff_df = pd.DataFrame([{'Name': 'Kelly', 'Role': 'Director of HR', 'Location': 'State Street'},
{'Name': 'Sally', 'Role': 'Course liaison', 'Location': 'Washington Avenue'},
{'Name': 'James', 'Role': 'Grader', 'Location': 'Washington Avenue'}])
student_df = pd.DataFrame([{'Name': 'James', 'School': 'Business', 'Location': '1024 Billiard Avenue'},
{'Name': 'Mike', 'School': 'Law', 'Location': 'Fraternity House #22'},
{'Name': 'Sally', 'School': 'Engineering', 'Location': '512 Wilson Crescent'}])
pd.merge(staff_df, student_df, how='left', left_on='Name', right_on='Name')
staff_df = pd.DataFrame([{'First Name': 'Kelly', 'Last Name': 'Desjardibs', 'Role': 'Director of HR'},
{'First Name': 'Sally', 'Last Name': 'Brooks', 'Role': 'Course liaison'},
{'First Name': 'James', 'Last Name': 'Wilde', 'Role': 'Grader'}])
staff_df
student_df = pd.DataFrame([{'First Name': 'James', 'Last Name': 'Hammond', 'School': 'Business'},
{'First Name': 'Mike', 'Last Name': 'Smith', 'School': 'Law'},
{'First Name': 'Sally', 'Last Name': 'Brooks', 'School': 'Engineering'}])
student_df
pd.merge(staff_df, student_df, how='inner', left_on=['First Name', 'Last Name'], right_on=['First Name', 'Last Name'])
Esta funcion toma algunos nombres de columna o nombre y divide el DataFrame en partes basandose en esos nombres. Esta funcion devuelve un objeto group by DataFrame, el cual puede ser iterado. Este objeto consiste de una tupla donde el primer elemento es la condición de soporte y el segundo elemento es el DataFrame reducido por esa agrupación.
df = pd.read_csv('./data/census.csv')
df.head()
# Excluimos por nivel de estado
df = df[df['SUMLEV'] == 50]
df
df.columns
df.shape[0]
df['STNAME'].unique()
%%timeit -n 10
for state in df['STNAME'].unique():
avg = np.average(df.where(df['STNAME'] == state).dropna()['CENSUS2010POP'])
print('Countries in state '+ state + ' have an average population of ' + str(avg))
%%timeit -n 10
for group, frame in df.groupby('STNAME'):
avg = np.average(frame['CENSUS2010POP'])
print('Countries in state '+ group + ' have an average population of ' + str(avg))
Para ordenas a nuestro gusto
c = df.groupby('STNAME')
c = c.sum()
c = c.sort_values(['CENSUS2010POP'], ascending=False)
c.head(10)
total_CENSUS2010POP = df.CENSUS2010POP.sum()
total_CENSUS2010POP
St_name = df.set_index('STNAME')
St_name
def fun(item):
if item[0] < 'M':
return 0
if item[0] < 'Q':
return 1
return 2
for group, frame in St_name.groupby(fun):
print('There are ' + str(len(frame)) + 'records in group ' + str(group) + ' for processing')
df = pd.read_csv('./data/census.csv')
df = df[df['SUMLEV'] == 50]
# El metodo aggregate recibo un diccionario, el cual contiene las columnas y una operacion para
# aplicar sobre cada una de ellas.
df.groupby('STNAME').agg({'CENSUS2010POP': np.average})
(df.set_index('STNAME').groupby(level=0)['CENSUS2010POP'].agg({'avg': np.average, 'sum': np.sum}))
Todas las funciones son aplicadas sobre todas las columnas
(df.set_index('STNAME').groupby(level=0)['POPESTIMATE2010', 'POPESTIMATE2011']
.aggregate({'avg': np.average, 'sum': np.sum}))
Que sucede cuando las etiquetas del diccionario son iguales a las de las columnas a operar
(df.set_index('STNAME').groupby(level=0)['POPESTIMATE2010', 'POPESTIMATE2011']
.agg({'POPESTIMATE2010': np.average, 'POPESTIMATE2011': np.sum}))
De acuerdo a los DataFrames creados en el ejercicio de fusion de datos
Realice las siguientes consultas usando el comando groupby